There was quite a kerfuffle recently about a feature being removed from Google Chrome. To be honest, the details don’t really matter for the point I want to make, but for the record, this was about removing alert and confirm dialogs from cross-origin iframes (and eventually everywhere else too).
It’s always tricky to remove a long-established feature from web browsers, but in this case there were significant security and performance reasons. The problem was how the change was communicated. It kind of wasn’t. So the first that people found out about it about was when things suddenly stopped working (like CodePen embeds).
The Chrome team responded quickly and the change has now been pushed back to next year. Hopefully there will be significant communication before that to let site owners know about the upcoming breakage.
So all’s well that ends well and we’ve all learned a valuable lesson about the importance of communication.
Or have we?
While this was going on, Emily Stark tweeted a more general point about breakage on the web:
Breaking changes happen often on the web, and as a developer it’s good practice to test against early release channels of major browsers to learn about any compatibility issues upfront.
Yikes! To me, this appears wrong on almost every level.
First of all, breaking changes don’t happen often on the web. They are—and should be—rare. If that were to change, the web would suffer massively in terms of predictability.
Secondly, the onus is not on web developers to keep track of older features in danger of being deprecated. That’s on the browser makers. I sincerely hope we’re not expected to consult a site called canistilluse.com.
I wasn’t the only one surprised by this message.
No, no, no, no! One of the best things about developing for the web is that, as a rule, browsers don’t break old code. Expecting every website and application to have an active team of developers maintaining it at all times is not how the web should work!
Most organizations and individuals do not have the resources to properly test and debug their website against Chrome canary every six weeks. Anybody who published a spec-compliant website should be able to trust that it will keep working.
This statement seriously undermines my trust in Google as steward for the web platform. When did we go from “never break the web” to “yes we will break the web often and you should be prepared for it”?!
It’s worth pointing out that the original tweet was not an official Google announcement. As Emily says right there on her Twitter account:
Opinions are my own.
Still, I was shaken to see such a cavalier attitude towards breaking changes on the World Wide Web. I know that removing dangerous old features is inevitable, but it should also be exceptional. It should not be taken lightly, and it should certainly not be expected to be an everyday part of web development.
It’s almost miraculous that I can visit the first web page ever published in a modern web browser and it still works. Let’s not become desensitised to how magical that is. I know it’s hard work to push the web forward, constantly add new features, while also maintaining backward compatibility, but it sure is worth it! We have collectively banked three decades worth of trust in the web as a stable place to build a home. Let’s not blow it.
If you published a website ten or twenty years ago, and you didn’t use any proprietary technology but only stuck to web standards, you should rightly expect that site to still work today …and still work ten and twenty years from now.
There was something else that bothered me about that tweet and it’s not something that I saw mentioned in the responses. There was an unspoken assumption that the web is built by professional web developers. That gave me a cold chill.
The web has made great strides in providing more and more powerful features that can be wielded in learnable, declarative, forgiving languages like HTML and CSS. With a bit of learning, anyone can make web pages complete with form validation, lazily-loaded responsive images, and beautiful grids that kick in on larger screens. The barrier to entry for all of those features has lowered over time—they used to require JavaScript or complex hacks. And with free(!) services like Netlify, you could literally drag a folder of web pages from your computer into a browser window and boom!, you’ve published to the entire world.
But the common narrative in the web development community—and amongst browser makers too apparently—is that web development has become more complex; so complex, in fact, that only an elite priesthood are capable of making websites today.
Absolute bollocks.
You can choose to make it really complicated. Convince yourself that “the modern web” is inherently complex and convoluted. But then look at what makes it complex and convoluted: toolchains, build tools, pipelines, frameworks, libraries, and abstractions. Please try to remember that none of those things are required to make a website.
This is for everyone. Not just for everyone to consume, but for everyone to make.
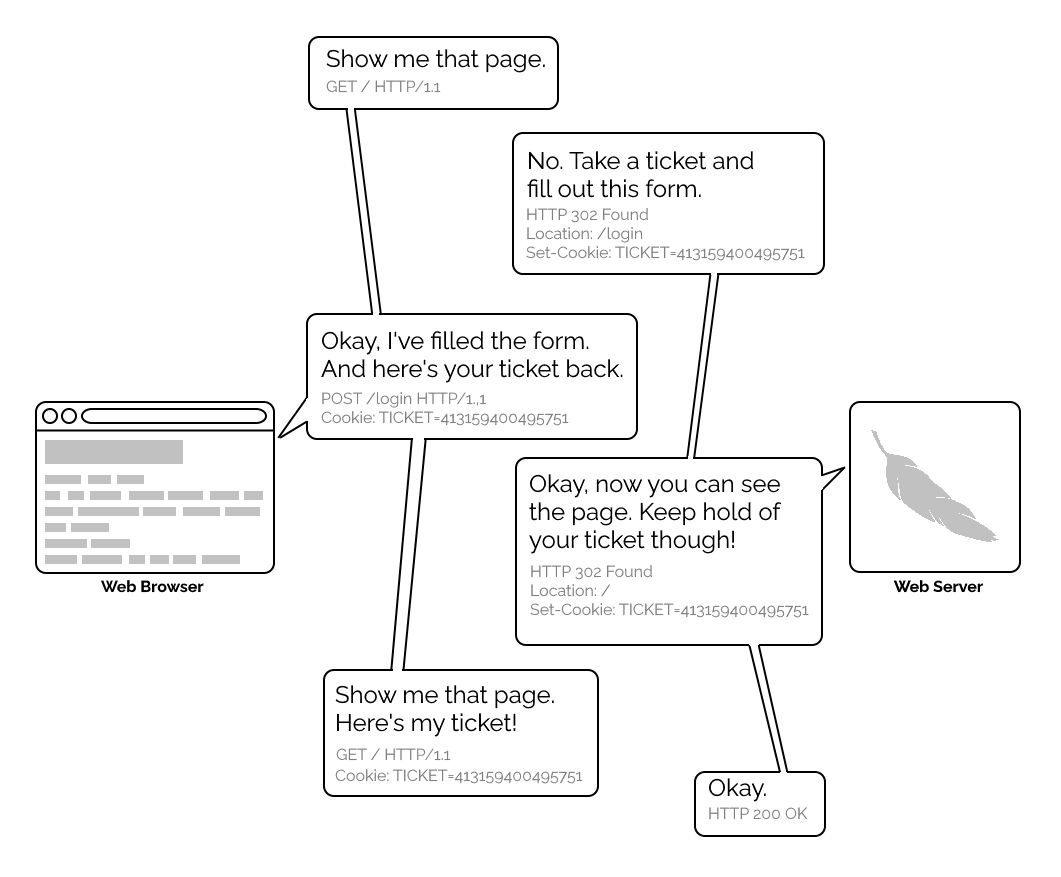{kind=link}
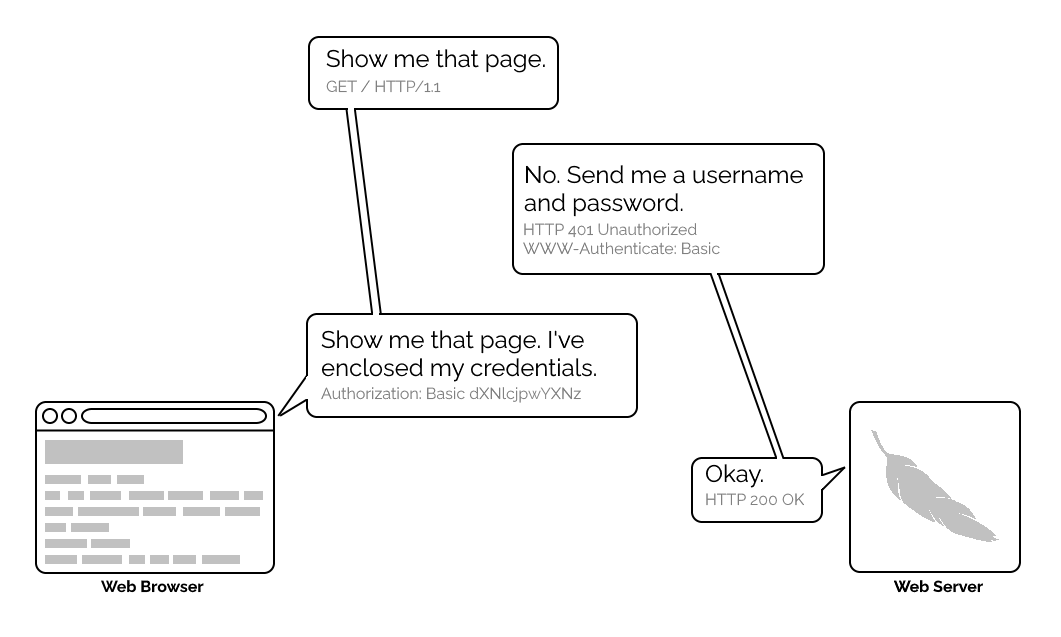{kind=link}
{kind=link}
{kind=link}
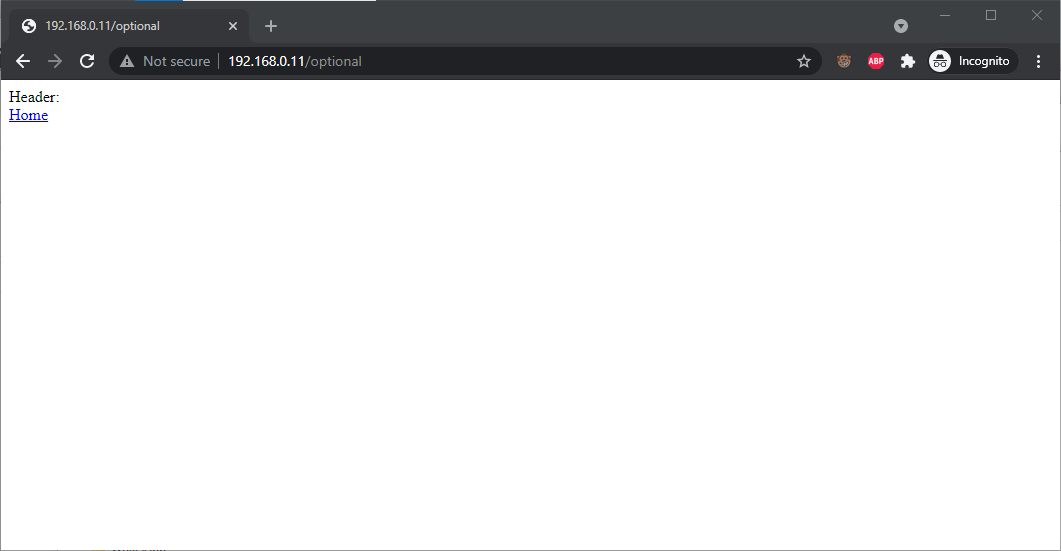{kind=link}
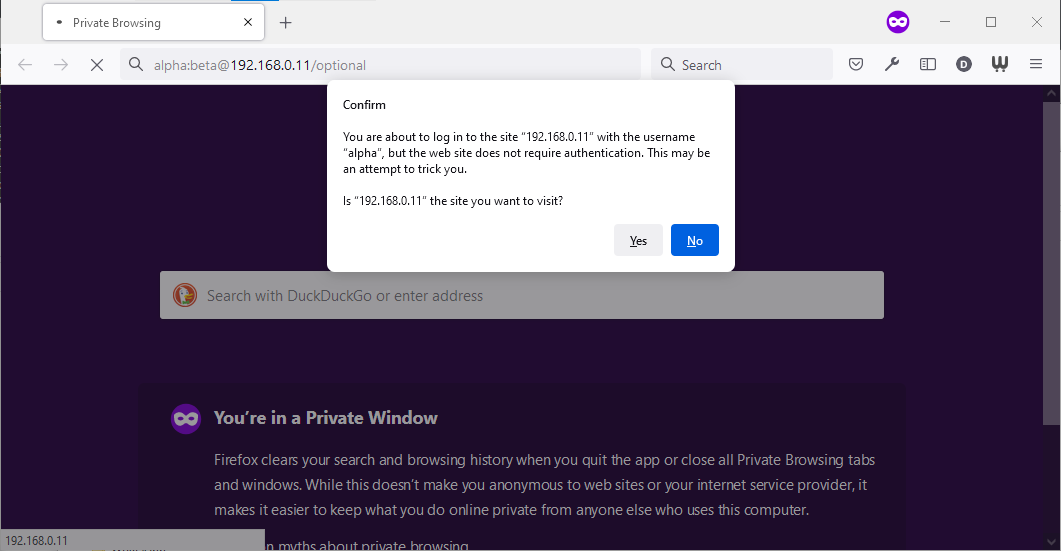{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1 Share
# Shared by Aleksi Peebles on Friday, August 6th, 2021 at 11:41am